Multimodal Emotional Understanding
Multimodal Emotional Understanding involves analyzing and integrating information from various modalities, such as text, audio, and visual cues, to accurately interpret human emotions and intentions. This approach enhances human-computer interaction and enables more responsive systems in applications like customer service, mental health monitoring, and social robotics, ultimately improving the user experience by providing more nuanced and context-aware responses.
We develop benchmarks for emotional understanding with Multimodal Large Language Models (MLLMs). We also design frameworks that integrate different cues to enhance emotion and intention recognition.
Highlight
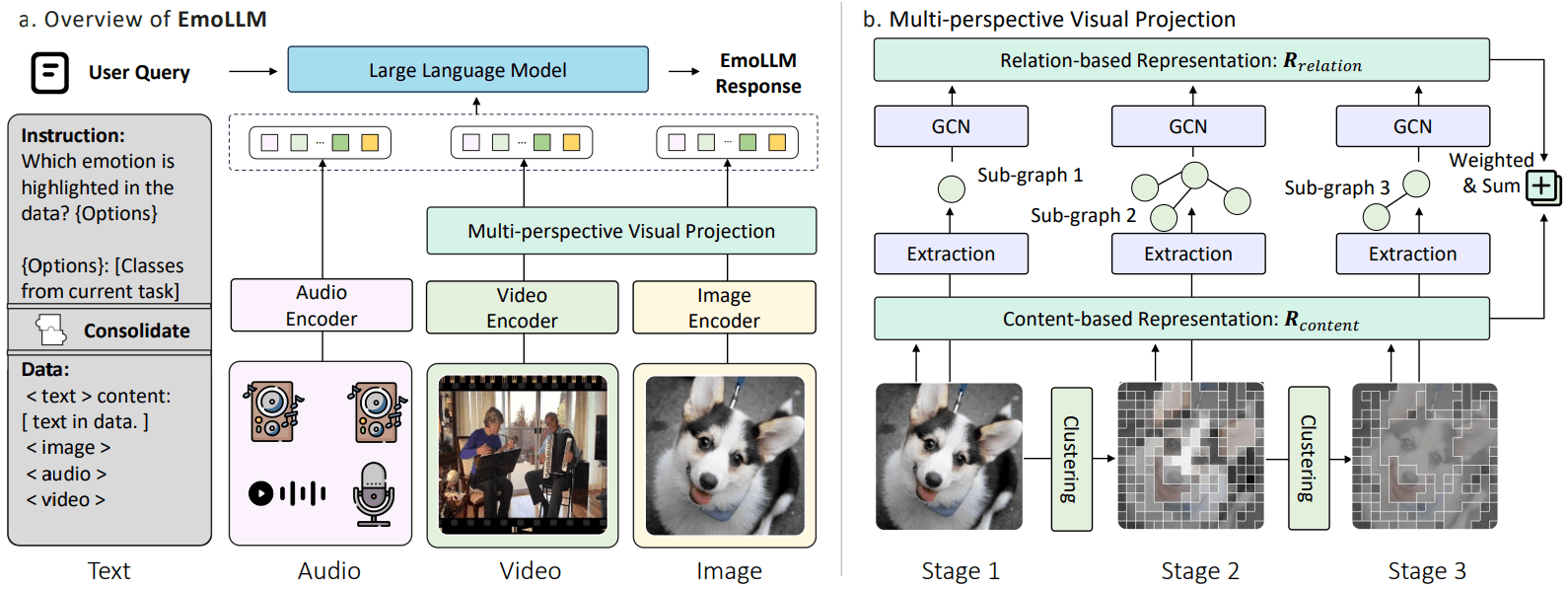
We introduce EmoBench, a comprehensive benchmark designed to enhance and evaluate the emotional understanding capabilities of MLLMs across a diverse range of tasks, providing a large-scale dataset of ~287k instructions. Besides, we propose EmoLLM, which incorporates Multi-perspective Visual Projection to capture diverse emotional cues and EmoPrompt to guide the reasoning process.
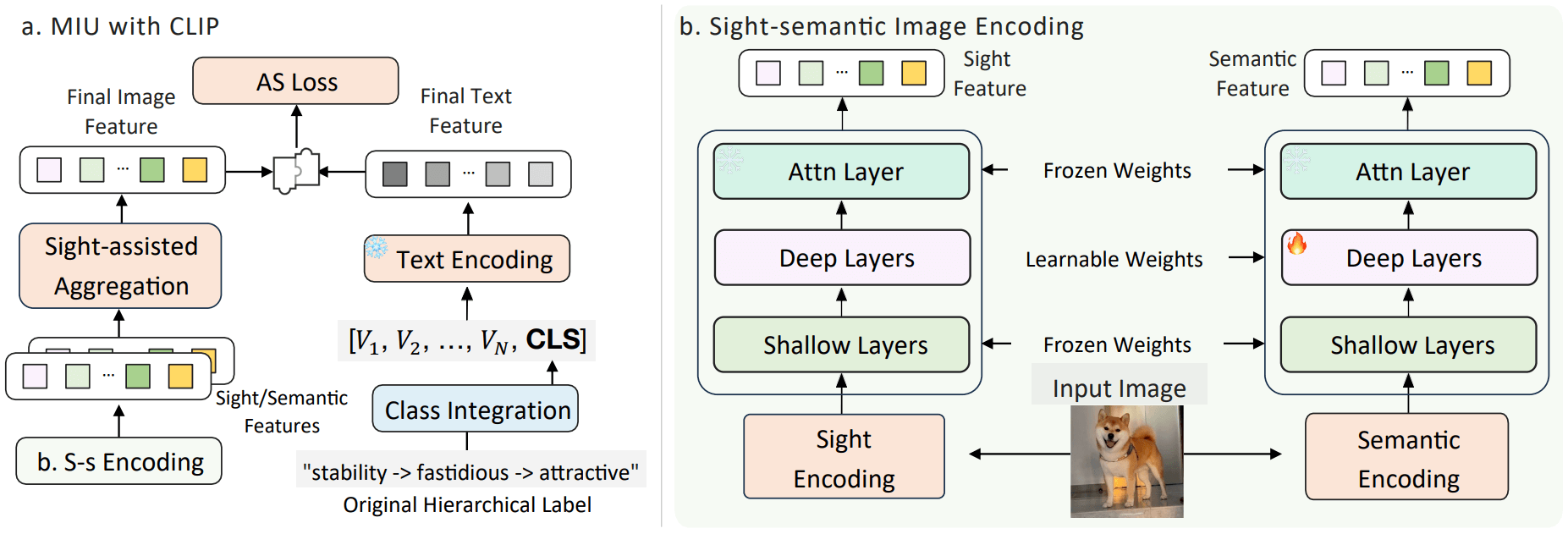
We introduce the IntCLIP framework, along with Hierarchical Class Integration, and the Sight-assisted Aggregation to effectively facilitate this adaptation. Their synergy is instrumental in guiding the extraction of intent cues and pinpointing key intention-related areas.
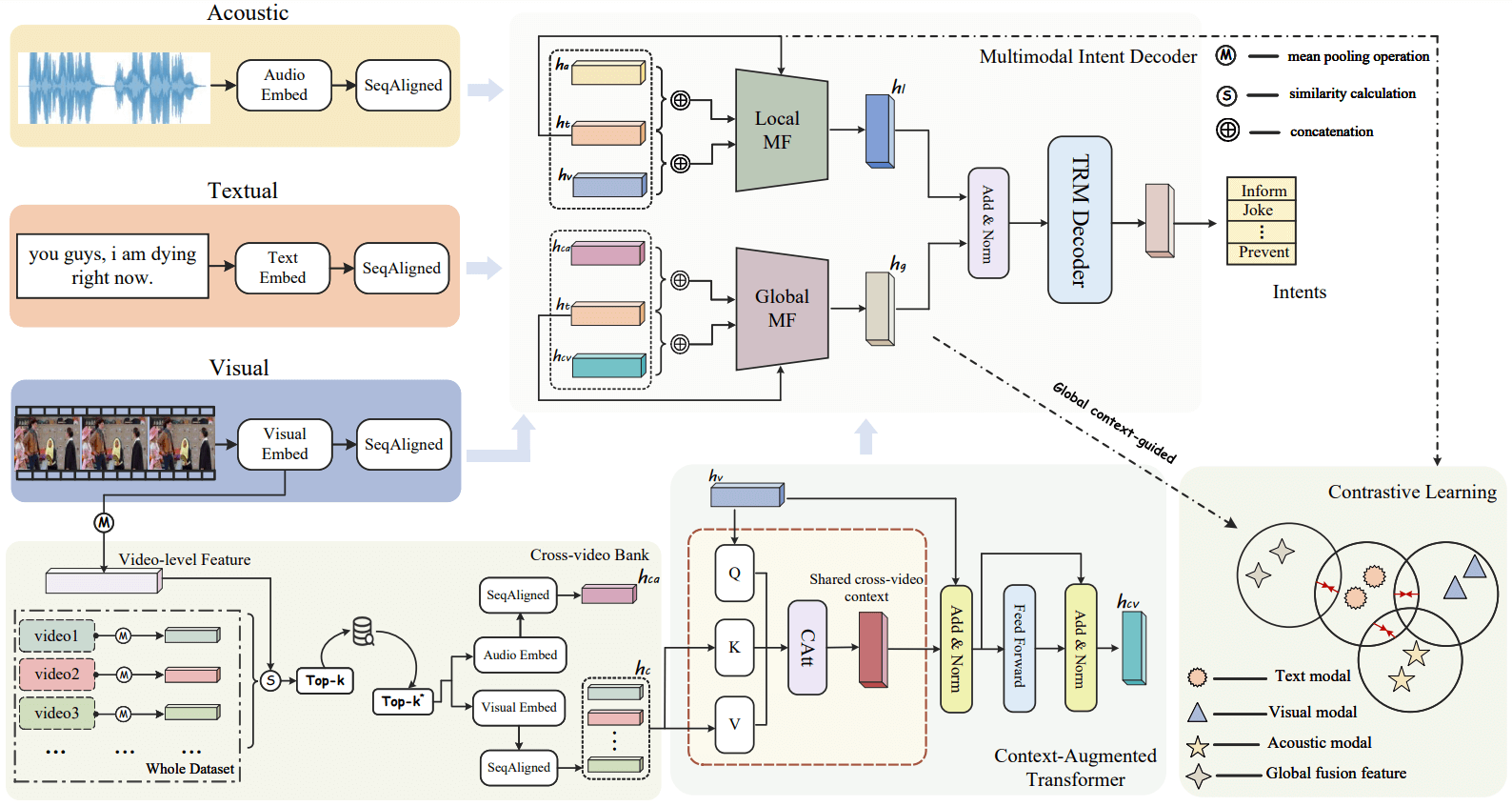
We propose a context-augmented global contrast (CAGC) learning method to mine rich global contextual cues from both intra-and cross-video to enhance intent understanding for multimodal intention recognition.
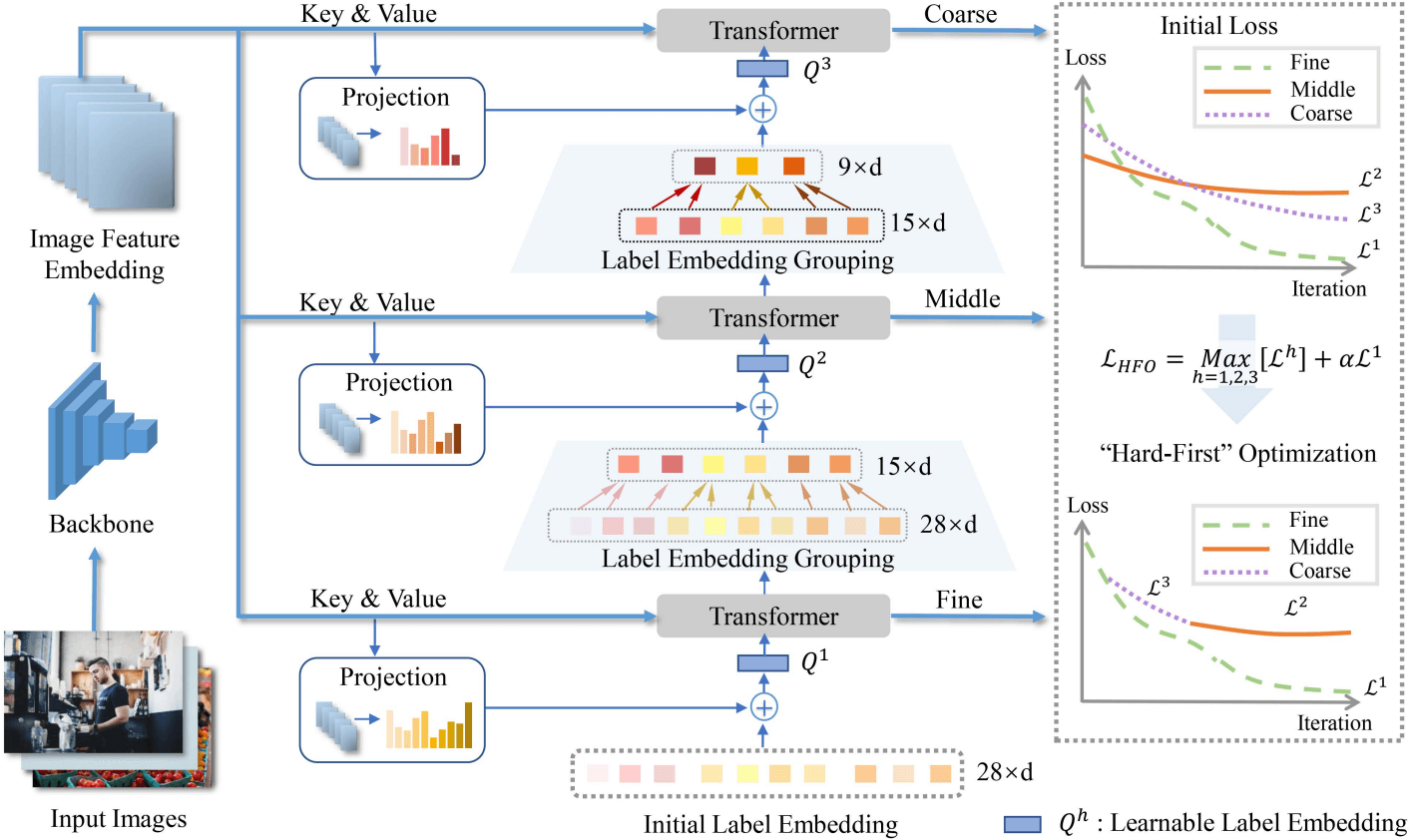
We provide a novel learnable Hierarchical Label Embedding and Grouping (HLEG) method for visual intention understanding corresponding for limited data and label ambiguity. It is featured in the following aspects: (1) Building a network with hierarchical transformer structure according to the hierarchical label tree in visual intention understanding. (2) Establishing the correlation between hierarchical and ambiguous labels with learnable label embedding and grouping. (3) Introducing a “Hard-First” optimization strategy between hierarchical classifications at multiple levels.