Research Projects
Our research primarily focuses on privacy-preserving multi-modal learning and its applications in multimedia analysis and reasoning:



- Object Re-Identification (Re-ID) aims to match the same object (e.g., persons, vehicles, animals) across multiple distinct views. Our work encompasses a wide range of directions, including cross-modal Re-ID, unsupervised Re-ID, domain generalized Re-ID, multi-species Re-ID, and UAV Re-ID.
- Multimodal Emotional Understanding aims to comprehensively analyze and interpret human emotions and intentions by leveraging multiple modalities. Our work integrates textual expressions, visual cues, acoustic features, and their intricate interactions to achieve a more nuanced and robust understanding of human emotional states and behavioral intentions.
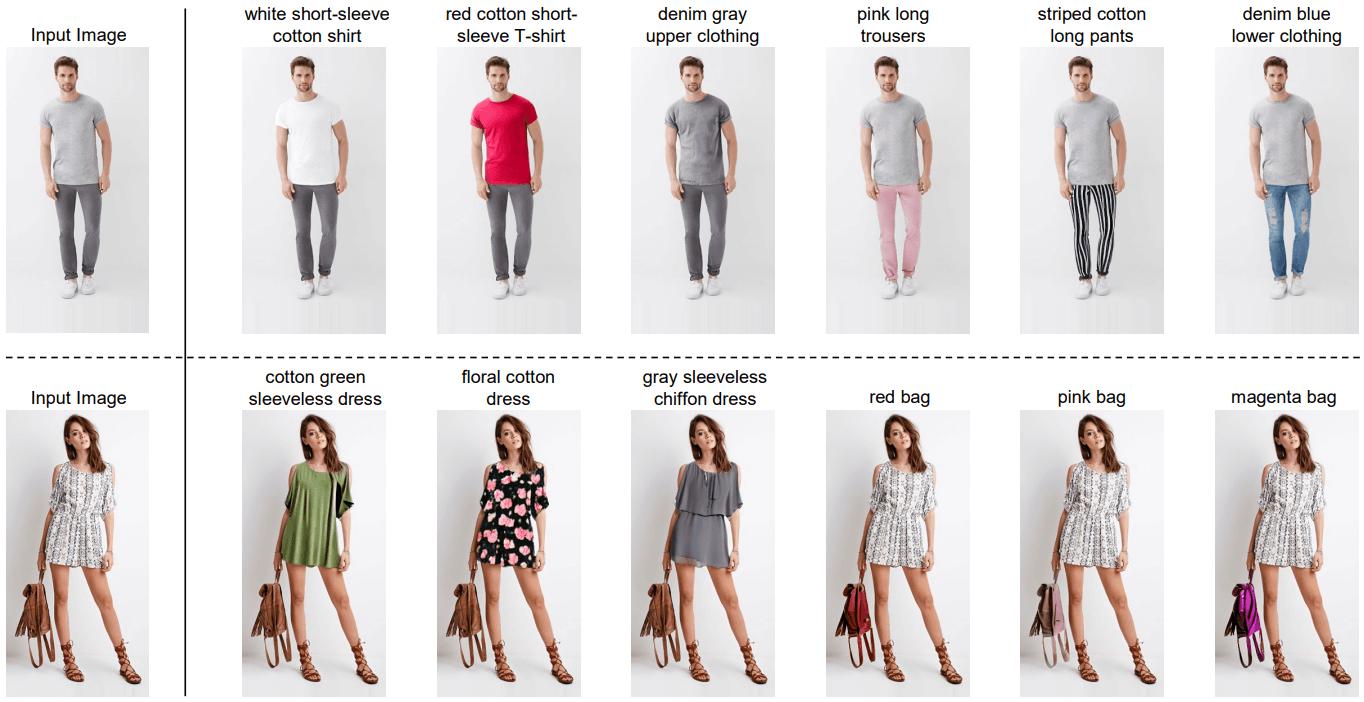
- Multimodal AI-Generated Content (AIGC) focuses on generating and synthesizing content across multiple modalities such as text, images, audio, and video through AI technologies. Our work spans several key areas in AIGC development, including text-guided fashion editing, and so on.
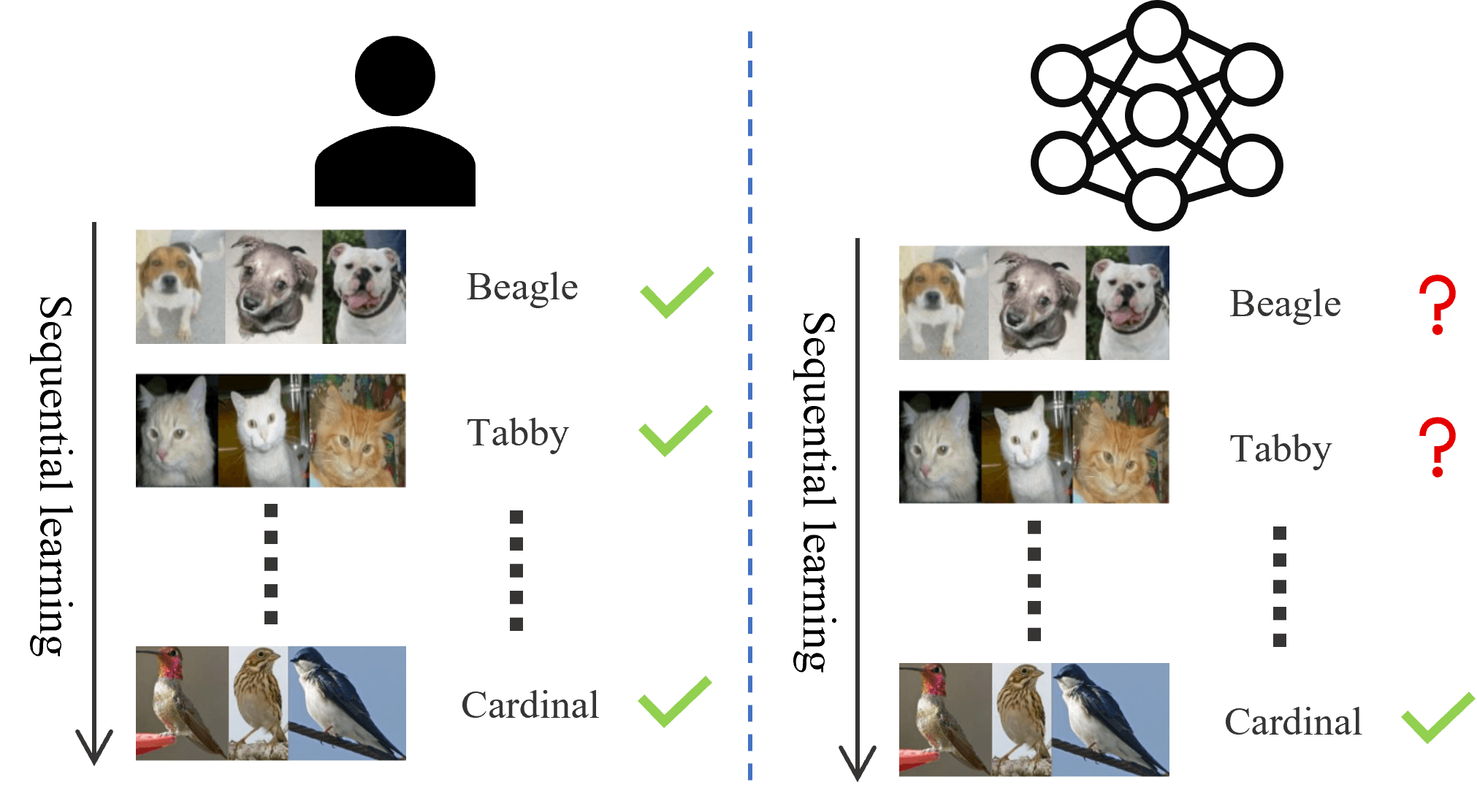
- Continual Learning, also known as incremental learning, aims to enable neural networks to acquire new information from continuous streams of training data while maintaining learned knowledge. Our work mainly covers challenging class incremental learning and incremental learning based on pre-trained vision language model.
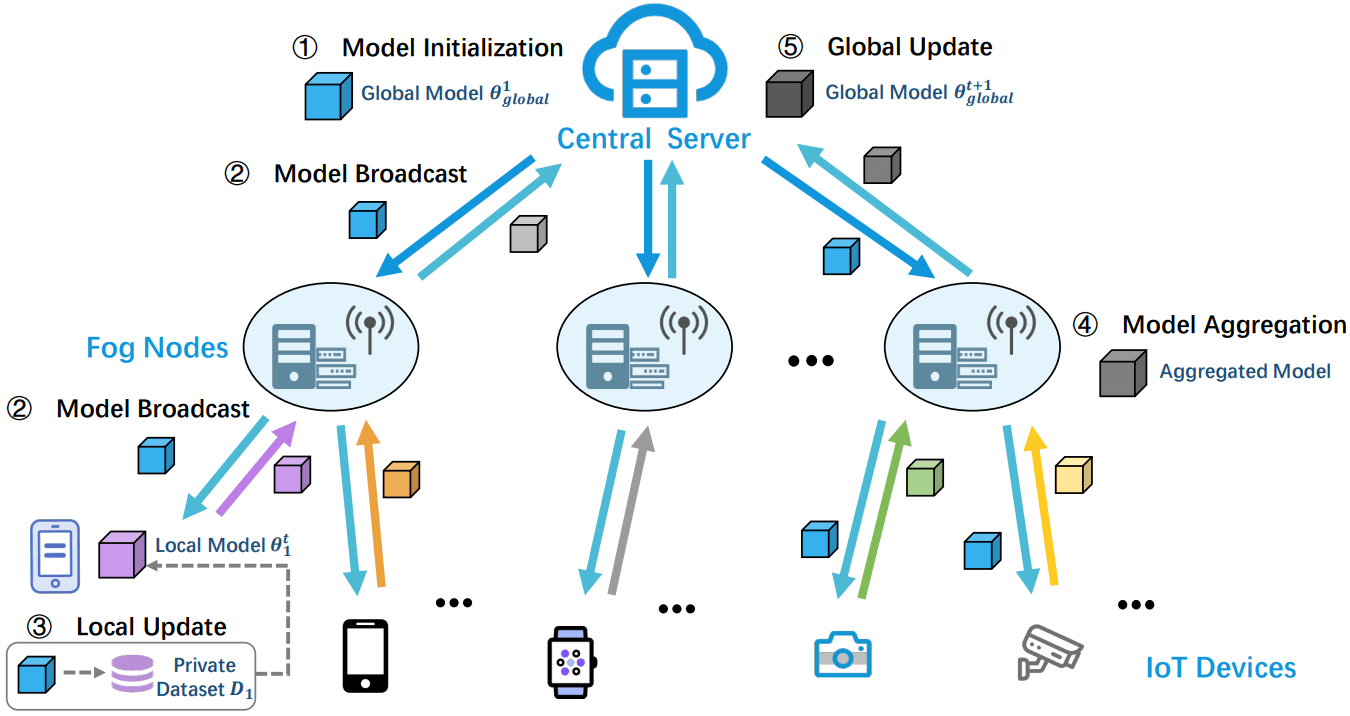
- Federated Learning is a decentralized approach to machine learning that enables multiple devices or institutions to collaboratively train a model without sharing their local data. Our work in Federated Learning covers various areas including Security, Generalization, Robustness in Federated Learning, and Federated Graph Learning.
- Multimodal Medical AI aims to integrate and analyze diverse types of medical data (e.g., images, clinical notes, genomic data) for comprehensive healthcare applications. Our research focuses on multimodal medical image analysis, with particular emphasis on developing interpretable AI systems, enhancing model generalizability, and ensuring fairness across diverse populations.
主持科研项目:
- 2022.01-2024.12 受限场景下的视频图像检索 国家自然科学基金优秀青年基金(海外)
- 2024.01-2027.12 面向生物特征认证的全域隐私保护和泛化的异构联邦学习研究 NSFC-RGC联合基金
- 2022.01-2025.12 面向复杂多变场景的行人重识别关键技术研究 国家自然科学基金面上项目
- 2024.12-2027.12 多模态大模型驱动的青少年心理健康智能分析与预警 科技部重点研发计划课题
- 2021.07-2023.12 基于无监督学习的监控目标检索关键技术研究 湖北省重点研发计划
- 2021.02-2022.12 开放场景下视觉学习理论及应用 中国科协青年人才托举项目
- 2024.01-2026.12 多模态精神疾病智能诊断及健康预测 泰康生命医学中心PI项目
- 2022.01-2024.12 面向空天应用场景的机器学习关键技术研究 湖北珞珈实验室专项基金
Terms of Releasing Implementation:
Software provided here is for personal research purposes only. Redistribution and commercial usage are not permitted. Feedback, applications, and further development are welcome. Contact yemang AT whu.edu.cn for bugs and collaborations. All rights of the implementation are reserved by the authors.